
ChatGPT
一个用于对话、获取见解和任务自动化的免费人工智能系统。
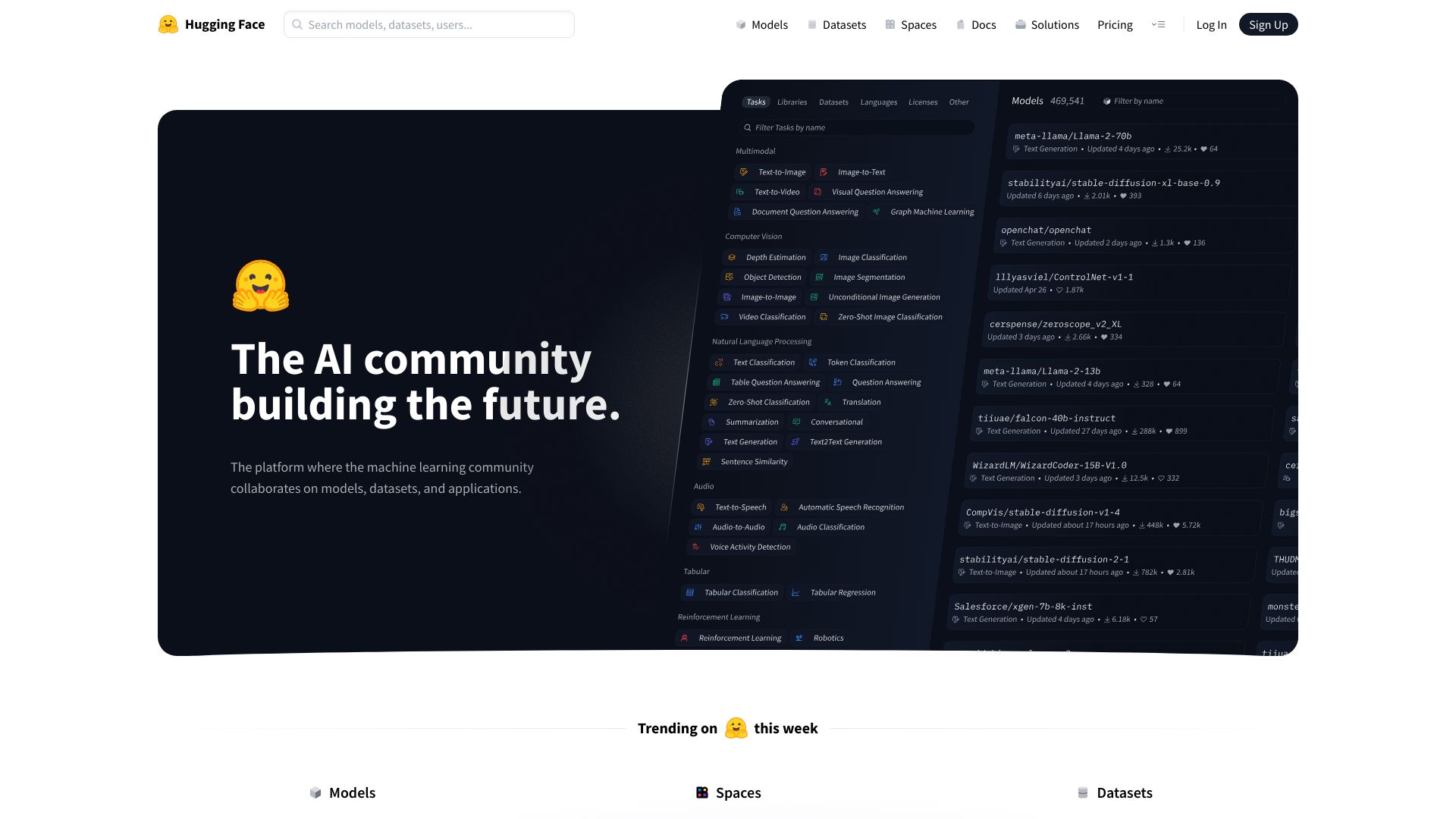
Hugging Face是一个专注于机器学习的开放人工智能社区和平台,致力于通过开源和开放科学构建未来。它被广泛誉为“AI界的GitHub”,为全球的机器学习研究人员、开发者和企业提供了一个协作、共享和部署AI模型、数据集和应用的综合生态系统。
定义: Hugging Face 是一个集AI模型、数据集、应用和开发工具于一体的开放平台,旨在推动人工智能的民主化和普及。
核心价值:
Hugging Face 解决了AI开发中的诸多痛点,其核心价值在于:
* 降低AI开发门槛: 通过提供大量预训练模型、标准化的库和API,极大地简化了AI模型的发现、使用、训练和部署过程,使开发者无需从零开始训练昂贵的模型,从而节省了大量时间和计算资源。
* 促进协作与共享: 构建了一个活跃的全球社区,鼓励开发者共享模型、数据集和应用,加速了AI技术的迭代与创新。
* 标准化AI工作流: 提供了统一的接口和工具,使得不同框架下的模型和数据集能够高效地协同工作,提升了开发效率和可复用性。
适用人群:
* AI研究人员与学生: 需要访问最先进的模型和数据集进行研究、基准测试和快速概念验证。
* 机器学习工程师与数据科学家: 旨在高效地构建、训练、微调和部署各种AI模型,特别是在自然语言处理 (NLP)、计算机视觉、音频和强化学习等领域。
* 企业与初创公司: 寻求安全可靠的AI模型托管、部署解决方案以及加速机器学习开发的工具。
* 应用开发者: 希望通过现有模型快速集成AI功能到自己的产品中,或展示AI应用演示。
Hugging Face 生态系统围绕几个关键组件构建,它们协同工作以简化机器学习工作流程:
Hugging Face Hub(模型与数据集中心)
Transformers 库
Hugging Face Spaces(AI应用托管平台)
Inference Endpoints(推理端点服务)
Datasets 库
以下是一个用户从零开始在Hugging Face上寻找并体验一个核心任务(例如:情感分析模型)的流程:
第一步:访问Hugging Face官网并注册/登录
* 打开您的浏览器,输入网址 https://huggingface.co。
* 点击右上角的“Sign Up”或“Log In”按钮。
* 您可以使用GitHub或Google账户快速注册/登录,也可以通过邮箱注册。完成注册后,您将拥有一个Hugging Face账户。
第二步:探索模型中心 (Model Hub)
* 登录后,您会进入Hugging Face Hub页面。在页面顶部的搜索框中,您可以输入您感兴趣的任务,例如“情感分析”(sentiment-analysis)或直接搜索“中文情感分析”(chinese sentiment analysis)。
* 搜索结果会列出大量相关的预训练模型。您可以根据模型的点赞数、下载量、发布时间、支持的语言或框架等筛选器进行排序和筛选。
第三步:选择并在线测试模型
* 点击进入您感兴趣的模型页面(例如,一个名为 uer/roberta-base-finetuned-jd-binary-chinese 的中文情感分析模型)。
* 在模型页面的右侧,通常会有一个“推理API”(Inference API)的交互窗口或“Demo”区域。
* 在输入框中输入一段待分析的中文文本,例如“这家店有点黑,鱼香肉丝也太难吃了。”
* 点击“Compute”或“Run”按钮,模型会即时返回分析结果,例如文本的情感倾向(正面/负面)和相应的置信度分数。
第四步:下载模型或集成到代码中 (可选)
* 下载模型: 如果您希望在本地环境中使用该模型,可以在模型页面找到“Files and versions”标签页,下载模型的权重文件和配置文件。 对于大型模型,可能需要使用 git lfs。
* 代码集成: Hugging Face提供了Python库transformers,让您能够轻松地在自己的项目中加载和使用模型。
* 安装库:pip install transformers
* 在Python代码中导入pipeline函数:from transformers import pipeline
* 初始化分类器并指定模型:classifier = pipeline(model="uer/roberta-base-finetuned-jd-binary-chinese", task="sentiment-analysis", device=0) (device=0 表示使用GPU,-1 表示使用CPU)。
* 调用分类器进行预测:preds = classifier("这家店有点黑,鱼香肉丝也太难吃了。")
* 打印结果:print(preds)
第五步:部署您的AI应用 (可选)
* 如果您想将自己的AI模型或演示应用分享给他人,可以使用Hugging Face Spaces。
* 在您的个人资料页面,点击“New Space”创建一个新的应用空间,选择Gradio或Streamlit等SDK,上传您的代码和模型。
* Spaces会自动为您部署应用,生成一个可访问的URL,供他人在线体验。
行业地位:
Hugging Face 已成为全球人工智能社区的中心枢纽,被公认为“AI界的GitHub”。它在推动AI技术民主化方面扮演着关键角色,通过提供开放的模型、数据集和工具,显著降低了开发人员使用先进AI模型的门槛。Hugging Face 的Transformers库已经成为自然语言处理领域的标杆,其平台托管了数百万个模型、数据集和AI驱动的应用程序。
用户口碑:
* 正面评价(Pros):
* 海量资源: 提供大量且多样的AI模型和数据集,涵盖NLP、CV、音频等多个领域,且持续更新。
* 开发便捷: 提供了标准化的函式库(如Transformers、Datasets)、API和网页界面,大大简化了模型的发现、训练和部署,节省了开发时间和成本。
* 活跃社区: 拥有庞大的开发者社区,支持知识共享、经验交流和协作开发,形成开放的AI生态。
* 部署灵活: 提供Spaces用于快速演示和Inference Endpoints用于生产级部署,支持自动扩缩和多种硬件配置。
* 负面评价/不足(Cons):
* 许可模糊性: 社区模型之间的授权可能不一致或模糊,许多仓库的许可证文本宽松,而有些使用限制性或自定义许可证,用户在使用前需要仔细验证。
* 质量参差不齐: 并非所有社区上传的模型都拥有完善的文档或已准备好用于生产环境,模型质量可能良莠不齐。
* API/设计摩擦: 部分用户反映API不够直观,生态系统存在一定程度的扩散。
* 安全漏洞: 曾有报道指出Hugging Face Spaces平台存在未经授权访问导致部分用户密钥泄露的事件,以及开源组件Datasets存在不安全特性,可能被利用进行供应链后门投毒攻击的风险。Hugging Face已采取措施应对这些安全问题。
重要信息:
* 融资背景: Hugging Face 在2021年完成了4000万美元的B轮融资,并在2022年企业估值突破20亿美元。
* 知名合作: 2023年2月,Hugging Face 宣布与亚马逊云计算服务(AWS)合作,将其产品集成到AWS生态系统中,并共同在AWS的Trainium芯片上运行BLOOM等下一代模型。
* 所获荣誉: 曾获得EMNLP 2020最佳Demo论文奖、开源社区最具影响力AI工具奖以及开发者选择年度最佳机器学习平台等荣誉。
* 发展历程: 公司成立于2016年,初期专注于开发青少年聊天机器人应用,后因其开源的Transformers库广受欢迎而转型,成为开放AI模型的平台。
Hugging Face 的收费模式是怎样的?
Hugging Face 提供免费的基础服务,包括访问大部分公开模型和数据集。同时,它也提供付费的增值服务,如Pro订阅(针对个人专业用户)、Team订阅和Enterprise企业级解决方案,以及按需计费的计算服务(如Inference Endpoints和Spaces的GPU升级)。 具体定价请以官网最新信息为准。
Hugging Face 如何保障用户的数据安全和隐私?
Hugging Face Hub 提供多项安全功能,包括私有仓库、访问令牌、多因素认证、提交签名、恶意软件扫描、资源组以及更高级的访问控制等。 对于企业用户,还提供数据位置控制、审计日志等功能。
Hugging Face 是否支持中文模型和中文界面?
Hugging Face 支持多语言模型,用户可以通过语言筛选器快速找到中文模型。 虽然平台界面主要为英文,但有许多中文社区资源和教程。
如何将Hugging Face上的模型部署到生产环境?
用户可以通过Hugging Face Inference Endpoints服务将AI模型部署到生产环境,该服务提供自动扩缩、企业安全和LLM优化。 此外,也可以将模型下载到本地进行部署,或使用Hugging Face Spaces托管演示应用。
Hugging Face Hub和GitHub有什么区别?
Hugging Face Hub 专注于托管和协作AI模型、数据集和应用,提供了专门针对机器学习工作流的工具和功能(如模型卡片、推理API),而GitHub是一个通用的代码托管和版本控制平台。Hugging Face常被称为“AI界的GitHub”。
我可以在Hugging Face上贡献自己的模型或数据集吗?
是的,Hugging Face 鼓励用户将自己的模型和数据集上传到Hub,与全球社区分享和协作。 这有助于推动AI技术的开放和发展。
Hugging Face是否提供AI模型的训练计算资源?
Hugging Face 的计算服务主要围绕推理端点和Spaces的托管运行提供。 此外,还提供AutoTrain服务,用户可以通过提供数据来训练或微调模型。
Hugging Face提供了哪些学习资源?
Hugging Face 官网提供了详尽的官方文档、教程,以及免费的NLP课程。 此外,活跃的社区也贡献了大量的博客文章、视频教程和实战案例。
Hugging Face有企业级解决方案吗?
Hugging Face 提供定制化的企业级解决方案,包括专属模型托管、数据安全隔离、单点登录(SSO)、高级访问控制、数据位置控制和优先技术支持等,以满足企业在安全性、合规性和扩展性方面的需求。
Hugging Face支持哪些深度学习框架?
Hugging Face 的Transformers库和整个生态系统支持多种主流深度学习框架,包括PyTorch、TensorFlow和JAX。


