
Runway
Runway是一家人工智能研究公司,提供媒体生成和创意工作流程的工具。
昇思MindSpore(简称MindSpore)是由华为自主研发并开源的一款全场景深度学习训练/推理框架。它旨在为人工智能开发者提供一个易开发、高效执行、全场景覆盖的平台,支持从云端、边缘到终端的广泛应用场景,并与华为昇腾(Ascend)AI处理器进行深度协同优化,以充分发挥硬件性能。
核心价值: MindSpore解决了当前AI开发中的多项痛点,其核心价值体现在:
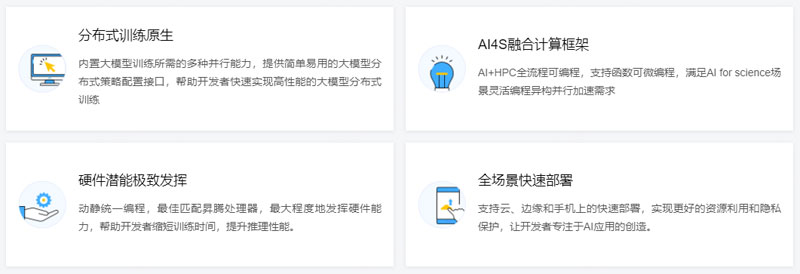
* 降低开发门槛: 通过提供友好的API和简化的编程范式,如一次编码即可实现单机与分布式训练,降低了数据科学家和算法工程师的开发复杂度,提升了开发体验。
* 提升执行效率: 框架在计算效率、数据预处理效率以及分布式训练效率方面进行了深度优化,通过图编译、算子融合、多卡并行等技术,确保模型训练和推理的高效执行。
* 实现全场景覆盖: 支持云、边缘、端侧等多种部署环境,实现了模型的训练-推理-全场景部署,使得AI能力能够广泛应用于不同设备和场景。
* 软硬件协同优化: 对华为昇腾AI处理器提供原生支持,并进行深度优化,能够最大化发挥昇腾芯片的算力优势。
适用人群: MindSpore主要面向以下用户群体:
* 数据科学家与算法工程师: 框架提供易用且高效的开发体验,帮助他们快速实现算法思路,进行模型开发与研究。
* AI应用开发者: 希望在云、边、端多种场景下部署和应用AI模型的开发者。
* 科研工作者: 在机器学习、深度学习及科学计算等领域进行研究的人员,MindSpore提供强大的科学计算能力。
* 企业级用户: 需要企业级安全与隐私保护功能,以及对抗鲁棒性、模型安全测试等增强功能的开发者。
MindSpore作为一个全场景深度学习框架,其核心功能包括:
自动微分 (Automatic Differentiation)
MindSpore内置了基于源码转换的通用自动微分机制,这使得开发者无需手动推导和编写复杂的梯度计算代码。它支持静态计算图和动态计算图相结合的模式,通过ms.grad等函数,用户只需定义前向计算过程,框架便能自动生成反向传播函数并计算梯度,极大地简化了神经网络的训练过程,提高了开发效率。 此外,MindSpore还支持高阶自动微分,这在科学计算和二阶优化等领域具有重要应用价值。
分布式并行训练 (Distributed Parallel Training)
随着深度学习模型规模的不断扩大,分布式并行训练成为提升训练效率的关键手段。MindSpore原生支持大规模并行训练,并提供了一套自动混合并行解决方案。 开发者无需编写复杂的分布式策略,只需在单机代码中添加少量配置代码,框架即可自动进行模型切分、代价模型建立和最优并行模式选择,从而实现数据并行、模型并行、流水并行和优化器并行等多种混合并行策略,显著降低了AI开发门槛和系统调优时间。
全场景部署 (All-Scenario Deployment)
MindSpore致力于实现模型在云、边、端全场景的统一训练和部署。 神经网络模型训练完成后,可以导出为端云统一的MindIR格式,这种格式与硬件平台解耦,实现了“一次训练,多次部署”的能力。 此外,MindSpore提供了轻量级的推理引擎MindSpore Lite,专门用于在移动端和嵌入式设备上进行模型推理,进一步扩大了AI在各类设备上的应用范围。
数据处理与增强 (Data Processing and Augmentation)
MindSpore提供了MindData模块,集成了高效的数据处理、常用数据集加载以及数据增强等功能和编程接口。 用户可以灵活定义数据处理流程,并通过pipeline并行优化提升数据预处理效率,为模型训练提供高质量的数据支持。
可视化调试调优工具 (Visualization and Debugging Tools)
MindSpore提供了MindInsight可视化调试调优工具,帮助开发者更好地理解和优化模型。 通过MindInsight,用户可以可视化地查看训练过程中的损失曲线、算子执行情况、权重参数等数据,方便进行调试、性能优化和精度问题分析。
本指南将模拟一个用户从零开始使用昇思MindSpore,完成一个简单的神经网络模型训练与推理的流程。
第一步:环境准备与安装
1. 安装Python: 确保您的系统已安装Python 3.7及以上版本。建议使用Conda创建独立的虚拟环境,以避免与其他Python项目产生冲突。
例如:conda create -n mindspore_env python=3.9
激活环境:conda activate mindspore_env
2. 选择MindSpore版本并安装: 访问MindSpore官网的安装页面(mindspore.cn/install),根据您的操作系统(Windows/Linux/macOS)、硬件类型(CPU/GPU/Ascend)和Python版本选择合适的MindSpore安装包或命令。
* 例如,安装CPU版本:pip install mindspore==版本号 -i https://pypi.tuna.tsinghua.edu.cn/simple (使用清华镜像加速下载)
* 如果使用Ascend处理器,还需要安装昇腾AI处理器配套软件包。
3. 验证安装: 安装完成后,在Python环境中运行以下代码验证:
python
import mindspore
print(mindspore.__version__)
如果能够正常输出版本号,则表示安装成功。
第二步:准备数据集
1. 下载数据集: MindSpore教程中常使用MNIST等经典数据集进行入门示例。您需要从MindSpore官网或其他公开渠道下载所需数据集,并解压到指定路径。
2. 数据处理: 使用mindspore.dataset模块对数据进行加载、预处理和增强操作,如图像裁剪、归一化、批量处理等。
第三步:构建神经网络
1. 定义网络结构: 在MindSpore中,神经网络模型通过继承mindspore.nn.Cell类来定义,并在construct方法中实现前向传播逻辑。
“`python
import mindspore.nn as nn
from mindspore import Tensor
class SimpleNet(nn.Cell):
def __init__(self):
super(SimpleNet, self).__init__()
self.flatten = nn.Flatten()
self.dense_relu_seq = nn.SequentialCell(
nn.Dense(28*28, 512),
nn.ReLU(),
nn.Dense(512, 512),
nn.ReLU(),
nn.Dense(512, 10)
)
def construct(self, x):
x = self.flatten(x)
logits = self.dense_relu_seq(x)
return logits
```
model = SimpleNet()第四步:定义损失函数与优化器
1. 损失函数 (Loss Function): 选择合适的损失函数来衡量模型预测值与真实值之间的差异,如交叉熵损失 (nn.CrossEntropyLoss)。
2. 优化器 (Optimizer): 选择优化器来更新模型参数以最小化损失函数,如Adam (nn.Adam) 或SGD (nn.SGD)。
python
loss_fn = nn.CrossEntropyLoss()
optimizer = nn.Adam(model.trainable_params(), learning_rate=1e-3)
第五步:模型训练
1. 创建训练函数: MindSpore使用函数式自动微分机制,您需要定义一个训练步骤函数,包含前向计算、损失计算、梯度反向传播和参数更新。
2. 进行训练: 迭代数据集进行多轮(epoch)训练。
“`python
from mindspore import ops
def train_step(data, label):
with ops.GradConverged(loss_fn)(model) as grad_fn:
logits = model(data)
loss = loss_fn(logits, label)
grads = grad_fn(data, label)
optimizer(grads)
return loss, logits
# 假设 train_dataloader 是已准备好的训练数据加载器
# for epoch in range(epochs):
# for data, label in train_dataloader:
# loss, _ = train_step(data, label)
# print(f"Epoch {epoch}, Loss: {loss.asnumpy()}")
```3. 保存模型: 训练完成后,保存模型的参数以便后续推理使用。
第六步:模型推理与验证
1. 加载模型: 加载已训练并保存的模型参数。
2. 定义测试函数: 定义一个函数来评估模型在测试集上的性能(如准确率)。
3. 进行推理与验证: 使用加载的模型对测试数据进行预测,并评估模型的准确性。
“`python
# 加载测试数据集
# test_dataloader = …
# 定义测试函数
def test(dataloader, model, loss_fn):
num_batches = dataloader.get_dataset_size()
model.set_train(False) # 设置为推理模式
total, correct = 0, 0
total_loss = 0
for data, label in dataloader:
pred = model(data)
total_loss += loss_fn(pred, label).asnumpy()
total += label.shape[0]
correct += (pred.argmax(1) == label).asnumpy().sum()
avg_loss = total_loss / num_batches
accuracy = correct / total
print(f"Test Error: \n Accuracy: {(100*accuracy):>0.1f}%, Avg loss: {avg_loss:>8f} \n")
# test(test_dataloader, model, loss_fn)
```
行业地位:
昇思MindSpore作为华为自主研发的开源AI框架,在中国AI框架市场中占据领先地位。根据国际权威数据调研机构IDC发布的《中国AI开源框架市场研究报告(2024)》,昇思MindSpore在2024年新增市场份额达到30.26%,位列中国框架第一,成为发展最快的自主创新开源框架。 另有报告预测,到2024年,昇思MindSpore在中国AI框架新增市场中的份额有望达到30%。 截至目前,MindSpore在全球范围内已跻身主流AI框架第一梯队,仅次于PyTorch。 它被视为AI行业中的基础设施,是AI开发者和科研工作者的重要工具。
用户口碑:
* 正面评价 (Pros):
* 易开发: 提供了友好的API和简洁的编程范式,降低了AI开发门槛,提升了数据科学家和算法工程师的开发体验。
* 高效执行: 在计算效率、数据预处理效率和分布式训练效率方面表现出色,通过图编译、算子融合等技术优化性能。
* 全场景覆盖: 支持云、边、端多种部署环境,实现了一次训练、多场景部署的能力。
* 与昇腾硬件深度协同: 对华为昇腾AI处理器进行原生支持和深度优化,能够最大化发挥硬件性能,特别在国产化和隐私计算领域具有巨大优势。
* 自动并行: 提供业界领先的全自动并行能力,大幅降低并行代码量和系统调优时间。
* 社区活跃与生态繁荣: 拥有庞大的社区用户和贡献者群体,积极孵化和适配主流大模型,并与众多企业、高校合作,共同构建AI开源生态。
重要信息:
* 开源背景: 昇思MindSpore于2020年3月28日由华为正式开源,旨在携手产业界和开发者共建AI开源框架生态。
* 社区成就: 截至目前,MindSpore社区拥有超过13.1M+社区用户,3.6K+总Star数,43.7K+总Issue数,120.3K+总PR数。 另有数据指出,其核心贡献者超过4万,全球用户下载量超过1100万,发表学术论文超过1700篇,在所有AI框架中排名中国第一、全球第二。
* 荣誉与认证: 昇思MindSpore获得了国际上首份AI框架CC EAL2+证书,标志着其在产品信息安全方面达到了业内领先水平,并逐步获得国际认可。
* 大模型支持: MindSpore已经孵化、适配了50多个国内外主流大模型,并帮助超过1700家企业、研究院所落地2000余个大模型解决方案,涵盖政府、交通、金融、医疗、驾驶等多个领域。 业界首个2000亿参数中文预训练语言模型“鹏程·盘古”以及面向生物医学领域的“鹏程·神农”大模型等均基于MindSpore推出。
1. 昇思MindSpore是免费的吗?
是的,昇思MindSpore是一个开源深度学习框架,用户可以免费下载和使用。
2. MindSpore支持哪些硬件平台?
MindSpore支持CPU、GPU以及华为昇腾(Ascend)AI处理器等多种硬件架构,并针对昇腾芯片进行了深度优化。
3. MindSpore主要支持哪些编程语言?
目前MindSpore主要提供基于Python的前端表达与编程接口。未来计划陆续提供C/C++等第三方前端的对接工作。
4. MindSpore如何保证数据安全和隐私保护?
MindSpore通过其Armour(安全增强库)模块,提供对抗鲁棒性、模型安全测试、差分隐私训练、隐私泄露风险评估、数据漂移检测等功能,以增强企业级运用时的安全与隐私保护。
5. MindSpore是否支持动态图模式?
MindSpore结合了动态图(PyNative模式)和静态图模式的优势,可以通过配置切换。动态图模式在调试时更为灵活。
6. MindSpore提供哪些学习资源?
MindSpore官网提供了丰富的学习资源,包括基本介绍、安装指南、教程、文档、视频课程、模型库、技术博客和社区论坛等,方便开发者学习和交流。
7. 如何获取MindSpore的帮助和支持?
您可以通过MindSpore官方社区、论坛、Gitee/GitHub仓库提交Issue,或参与社区活动来获取帮助和支持。
8. MindSpore的模型可以部署到哪些场景?
MindSpore模型可以部署到云端服务器、边缘设备和移动终端等全场景,通过MindIR统一格式实现一次训练、多场景部署。
9. MindSpore在科学计算领域有哪些应用?
MindSpore在科学计算领域具有广泛应用,如分子动力学模拟、AI求解微分方程、地球系统模拟、蛋白质结构预测等,通过MindScience科学计算行业套件加速科学行业应用开发。
10. MindSpore与TensorFlow、PyTorch等其他深度学习框架有何不同?
MindSpore与TensorFlow、PyTorch均为深度学习框架,但MindSpore在设计上更强调易开发、高效执行和全场景覆盖,并对华为昇腾AI处理器进行深度优化。其独特的自动并行和端云统一的MindIR格式也是其重要特点。





